Behavior Modeling and Text Mining for Learning Analytics
Major Contributor: Chen Qiao (cqiao@connect.hku.hk)
Discovering Student Behavior Patterns from Event Logs: Preliminary Results on A Novel Probabilistic Latent Variable Model
- Abstract
Digital platforms enable the observation of learning behaviors through fine-grained log traces, offering more detailed clues for analysis. In addition to previous descriptive and predictive log analysis, this study aims to simultaneously model learner activities, event time spans, and interaction levels using the proposed Hidden Behavior Traits Model (HBTM). We evaluated model performance and explored their capability of clustering learners on a public dataset, and tried to interpret the machine recognized latent behavior patterns. Quantitative and qualitative results demonstrated the promising value of HBTM. Results of this study can contribute to the literature of online learner modelling and learning service planning.
- Approach: Probabilistic Latent Variable Modeling, Bayesian Network, MCMC
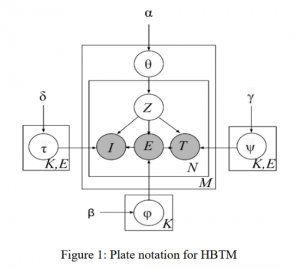
HBTM models the process of a learner conducting an event on the online learning environment. The learned traits can be used to interpret and categorize learners.
For a learner to conduct an event:
1. The current leading hidden trait Z stands out;
2. The event E to be conducted is decided under the influence of trait Z;
3. According to the trait Z and the event E, the interactivity level I (mouse and keyboard strokes), as well as the time span T are determined.
4. With the event, time span and interactivity level determined, a event occurs.
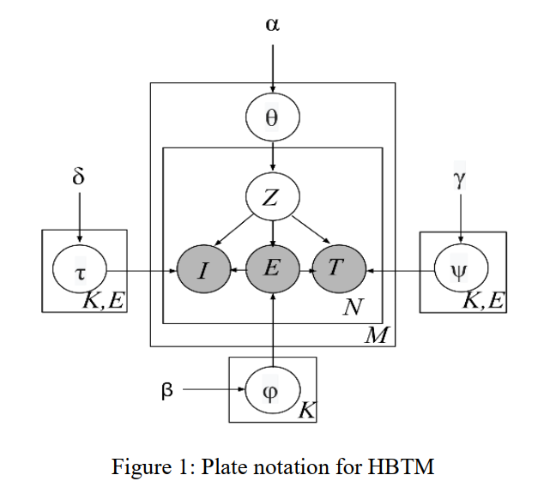
- Results: Example Behavior Patterns (Partial)
1. Event 14 and 15 are more likely to be off-topic events, while event 9 implies that the student is taking initiative trials to set up and observe simulation experiments
2. For off-topic event 15, he/she impacted by Trait 13 is more likely to spend more time (9~30 seconds) than those impacted by Trait 19 (0~9 seconds).
3. Much more mouse clicks and keystrokes are likely to be made in the off-topic events (Events 14 and 15) given Trait 13 than those given Trait 19.
4. Trait 13 as a less focused behavior pattern, while Trait 19 is a more focused behavior pattern and may imply in-depth learning.
{kind=link}
- Publication:
Qiao, C., & Hu, X. (2018, July). Discovering Student Behavior Patterns from Event Logs: Preliminary Results on A Novel Probabilistic Latent Variable Model. In 2018 IEEE 18th International Conference on Advanced Learning Technologies (ICALT) (pp. 207-211). IEEE.
Measuring The Gaps of Knowledge Between Texts by Computing Over Networked Representations
- Abstract
Gaps between knowledge sources are interesting to various stakeholders: they might indicate potential misconceptions awaiting correction, complex or novel knowledge that requires careful delivery or studying. Motivated by these underlying values, this study explores the knowledge gap phenomenon in the context of student textual responses. Leveraging the proposed method, discourses are first mapped into structured knowledge spaces where gaps between correct/incorrect responses and assessed knowledge are measured by network-based metrics. Empirical results demonstrate the effectiveness of the proposed method in measuring gaps in student responses. The networked representation of texts proposed in this study is novel in quantitatively framing gaps of knowledge. It also offers a set of validated metrics for analyzing student responses in research and practice.
(This is study 1 of Chen Qiao’s thesis project)
- Approach: Network Analysis, Optimization
Key idea:
– Representing knowledge with a networked scheme;
– Gaps between two knowledge networks can be evidenced via the merging operation;
– Structure dynamics of the networks after and before merging behave differently with or without gaps;
– Compute metrics based on network indices characterizing different aspects of the network structures.
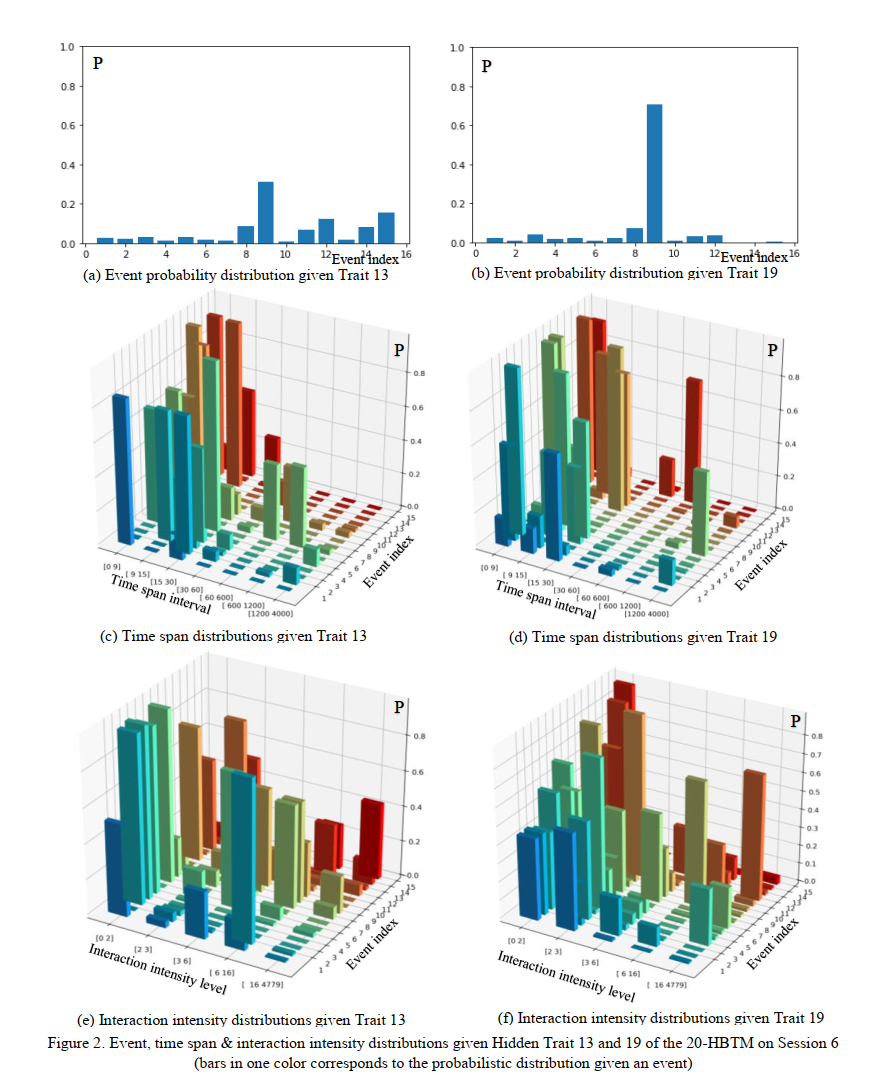
Example:
Assessment Knowledge (AK):
“Water and other materials necessary for biological activity in trees are transported throughout the stem and branches in thin, hollow tubes in the xylem, or wood tissue”.
Two responses:
A. stems transport water to other parts of the plant by converting water to food. (Incorrect)
B. stems transport water to other parts of the plant through a system of tubes. (Correct)
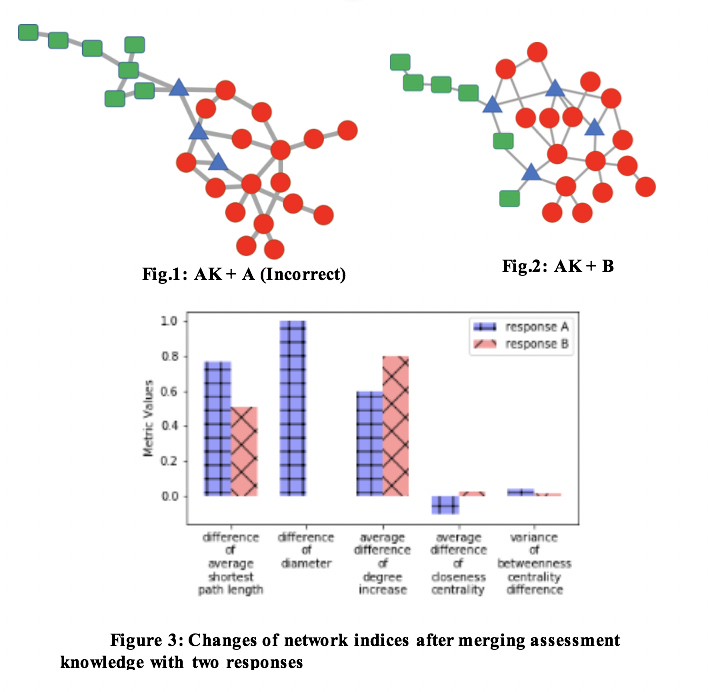
- Evaluation Results
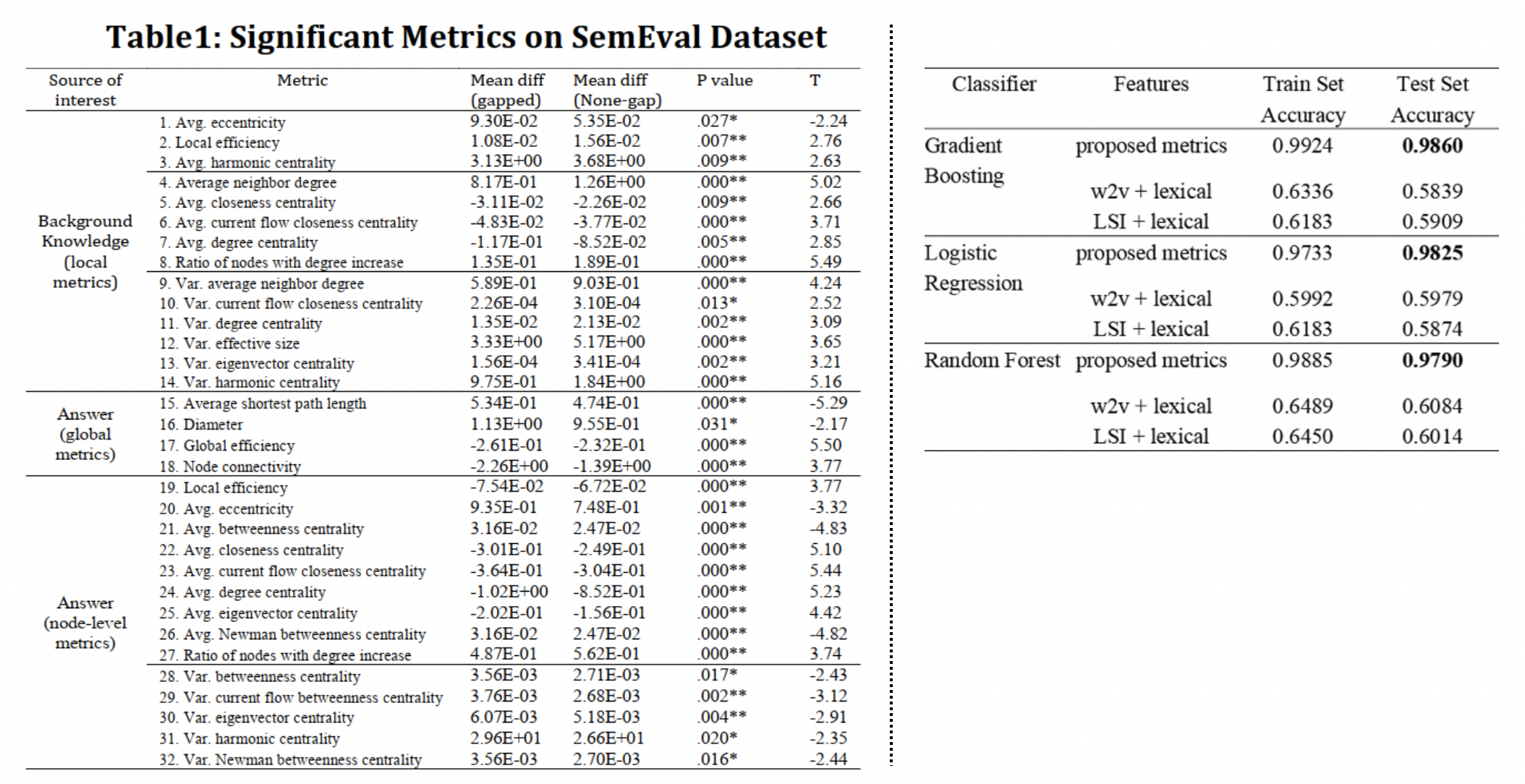
▶︎ Significant metrics (abbreviations: Assessment knowledge network (AKN), Correct Response Network (CRN), Incorrect Response Network (IRN))
Dynamics of AKN after and before merging:
– Variance of local nodes: local structures of the AKN after merging with CRN changed more evenly across all nodes than those after merging with IRN.
– Distance and Efficiency metrics: merging with CRN makes AKN less dispersed than merging with IRN.
– Assortativity and Updating state metrics: more nodes are associated with CRN than with IRN.
– Centrality metrics: centrality of AKN nodes decreased less after merging with CRN than with IRN.
Dynamics of response knowledge graph after and before merging:
– Variance of local nodes: more nodes in CRN were merged in similar manners, so that less extreme cases (no merging or become bridging nodes) occurred than in IRN.
– Distance and Efficiency metrics: Nodes of CRN are more likely to connect with central nodes of AKN than peripheral nodes as IKN does, so the distance increased less and efficiency decreased less.
– Centrality metrics: centrality of CRN increased more or decreased less after merging than IRN.
– Updating state metrics: CRN has more nodes associated with AKN than IRN.
▶︎ Prediction Powers
The proposed metrics outperformed the baseline features.
- Publication:
Qiao, C., & Hu, X. (2019). Measuring Knowledge Gaps in Student Responses by Mining Networked Representations of Texts. Paper presented at the Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA.
Text classification for cognitive domains: A case using lexical, syntactic and semantic features
- Abstract
Various automated classifiers have been implemented to categorise learning-related texts into cognitive domains. However, existing studies have applied limited linguistic features, and most have focused on texts written in English, with little attention given to Chinese. This study has tried to fill the gaps by applying a comprehensive set of features that have rarely been used collectively in previous research, with a focus on Chinese analytical texts. Experiments were conducted for classifier learning and evaluation, where a feature selection procedure significantly improved the classification performance. The results showed that different types of features complemented each other in forming strong collective representations of the original texts, and the discriminant nature of the features can be reasonably explained by language usage phenomena. The proposed approach could potentially be applied to other datasets of analytical writings involving cognitive domains, and the text features explored could be reused and further refined in future studies.
- Approach: Feature-Based Classification Problem, Feature Engineering via lexicon, Semantic and Syntactic Parsing, Feature Selection & Regularization to Counteract Overfitting
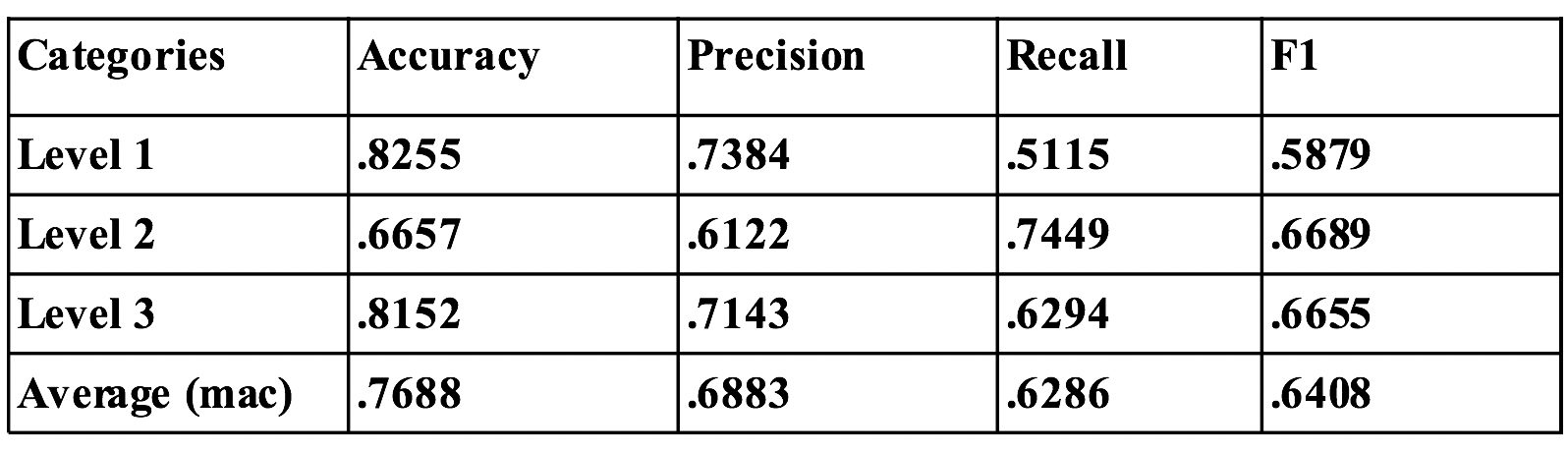
- Results
The proposed features obtained best performance.
Part of the features can indicate daily linguistic usage patterns.
- Publication:
Qiao, C., & Hu, X. (2018). Text classification for cognitive domains: A case using lexical, syntactic and semantic features. Journal of Information Science. https://doi.org/10.1177/0165551518802522
A Joint Neural Network Model for Combining Heterogeneous User Data Sources: An Example of At-risk Student Prediction
- Abstract
Information service providers require evidence from multiple data sources to characterize users and offer personalized service. In education, machine learning has been used to detect “at risk” students who are likely to fail in academic learning, so that interventions can be timely offered to individual learners. However, previous works have been exploiting either static features extracted from students’ profiles or dynamic ones extracted from event logs of human-computer interactions. Little research has been conducted to combine the two data sources which are potentially complementary to each other. Aimed to fill the gap and offer a strategy for the more broad problem of combining heterogeneous data sources, this study proposes a novel neural network model and explored its performance alongside various baselines with a range of conventional model-feature configurations. A thorough evaluation was conducted on an open dataset collected from online learning management systems, and the result demonstrated the good predictive performance of the proposed method. Implications of the findings on further research and applications of joint models are discussed.
- Approach: Deep Neural Networks, Machine Learning, Joint Training
Model architecture:
1. A Recurrent Neural Encoder (with LSTM cells) encodes the information from log event series.
2. A Linear Encoder encodes static profile features.
3. Information from the two heterogeneous sources interacts in the higher hidden layers and collectively contribute to the
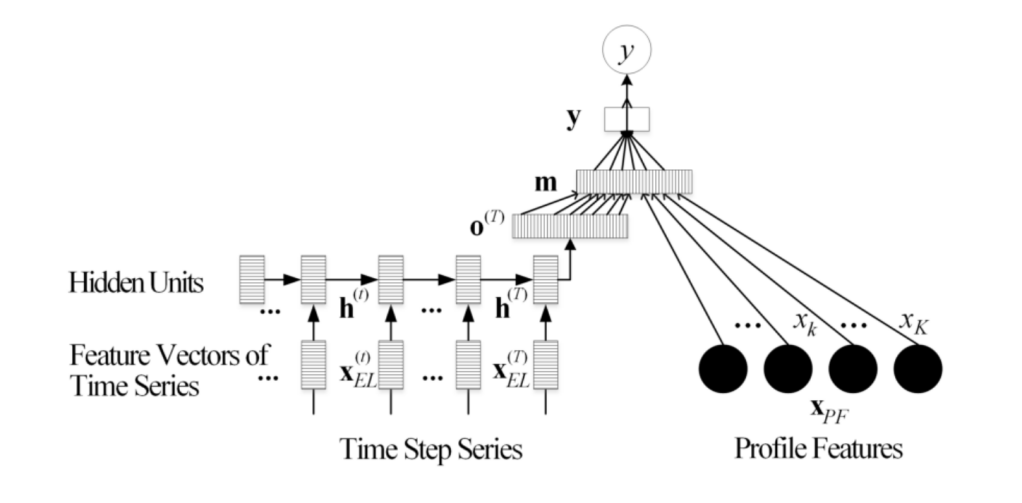
- Results
Obtained the Best Test F1 Scores on datasets of three courses from the Open University Learning Analytics Dataset (OULAD).
